
Block Cipher Algorithm Identification Scheme Based on Hybrid Gradient Boosting Decision Tree and Logistic Regression Model
-
摘要: 针对密码算法识别工作中因密码算法数量增多、密文数据复杂化以及数据间干扰增加,导致单层识别方案的识别准确率和稳定性变差等问题,提出一种基于混合梯度提升决策树和逻辑回归模型,并基于该模型构造分组密码算法识别方案。在该方案中,首先,采用NIST随机性测试标准中的15种测试方法作为密文特征提取方法对密文文件进行特征提取,并选定有意义的10种特征值作为分类器的输入;然后,使用这10组特征训练梯度提升决策树模型,并利用其学习而生成的树来构造新特征;最后,将这些新特征做one-hot编码,并将其加入到原有特征中训练逻辑回归模型进行预测。在唯密文情况下,基于9种不同的分类器模型分别构造9种不同的密码算法识别方案,并利用这9种方案对2种典型的分组密码算法AES和3DES加密的不同大小的密文文件进行密码算法二分类实验,对5种常用的分组密码算法AES、3DES、Blowfish、CAST和RC2加密的不同大小的密文文件进行密码算法五分类实验。实验结果表明,相较于其他识别方案,当密文长度相同时,本文所提方案在二分类和五分类识别问题中几乎均有最高的识别准确率。同时,随着密文长度的变化,识别准确率呈波动性变化,本文所提方案波动幅度最小,受影响程度最小,稳定性最高。Abstract: To solve the problems that the identification accuracy and stability of the single-layer identification scheme are deteriorated due to the increase in the number of cryptographic algorithms, the complexity of ciphertext data and the increase of interference between data, a hybrid gradient boosting decision tree and logistic regression (HGBDTLR) model were proposed, and a block cipher algorithm identification scheme based on this model (HGLBIS) was constructed. In this scheme, 15 NIST randomness testing methods were used as the ciphertext feature extraction methods to extract features from the ciphertext files, and 10 meaningful feature values were selected as the input to the classifier; then these 10 feature values were used to train a gradient boosting decision tree model, and the trees generated from its learning were used to construct new features; finally, the new features were one-hot encoded, and added to the original features to train the logistic regression model. In the ciphertext only scenario, nine different cryptographic algorithm identification schemes were constructed based on nine different classifier models. Then, these nine schemes were used to perform binary classification of block ciphers experiments on ciphertext files of different sizes encrypted by two typical block cipher algorithms AES and 3DES, and five classification of block ciphers experiments on ciphertext files of different sizes encrypted by five commonly-used block cipher algorithms AES, 3DES, Blowfish, CAST and RC2. The experimental results showed that, compared with the existing identification schemes, when the size of ciphertext files is the same, the scheme proposed in this paper has almost the highest identification accuracy on both the binary classification and five classifications of block ciphers. At the same time, with the change of the size of ciphertext files, the identification accuracy shows a fluctuating change. In conclusion, the proposed scheme has the smallest fluctuation range, the smallest degree of influence and the highest stability.
-
随着密码算法的广泛应用,密码算法的安全性受到人们的广泛关注。目前大多数的密码分析技术都是基于密码算法已知的前提下,开展对各种密码算法的分析。然而在实际工作中,密码分析者通常仅能获取密文数据,而不知道所采用的具体密码算法。在这种情况下,密码破译时只能进行唯密文分析。同时,随着应用场景和通信环境的日益复杂,各种加密算法层出不穷,实际应用中获得的密文长度不同,密钥不同,密码算法的识别需考虑更广范围的密码算法集合。因此,高效地识别密文所使用的密码算法成为密码分析的先决条件,开展密码算法识别研究具有非常重要的理论意义和实用价值。
密码算法识别最初的研究对象是古典密码算法。随着现代密码技术的飞速发展,传统的基于统计学方法的密码算法识别技术逐渐失效,研究者们提出了一系列基于机器学习方法的密码算法识别方案,这些方案具有以下两个特点:
1)识别方案主要围绕分组密码算法识别展开。如赵志诚[1]利用随机森林模型对随机生成的图片使用AES、DES、3DES、IDEA、Blowfish和Camellia 6种密码体制在ECB工作模式下加密产生的密文进行区分。
2)识别方案主要在ECB及CBC模式下对密文进行区分。如Dileep等[2]提出了一种利用支持向量机识别分组密码加密算法的方法,对AES、DES、TDES、RC5和Blowfish密码算法在ECB与CBC模式下的加密密文进行了区分实验,结果表明使用高斯核函数的支持向量机模型有最好的性能。此外,ECB模式相较于CBC有更好的识别准确率;de Mello等[3]分析了在ECB和CBC两种模式下由ARC4、Blowfish、DES、Rijdael、RSA、Serpent和Twofish等7种密码算法加密得到的密文文件,ECB在几乎所有密码算法上都能实现完全识别。
结合模式识别和机器学习的密码算法识别也受到越来越多研究者的关注。de Souza等[4]提出了一种基于自组织神经网络借助语言和信息检索方法的分组密码识别方案,通过聚类和分类过程,实现对密文所属密码体制的分类识别。吴杨等[5]提出了一种基于密文随机性度量值分布特征的两层识别方案,上层由K均值聚类算法对密码算法进行聚类划分,下层基于聚类的结果,通过进一步优化特征向量来区分密码算法,达到接近90%的分类准确率。在分层识别方案中,黄良韬等[6]结合已有的密码算法识别研究成果,提出了CM-簇分、CSN-簇分和CSBP-簇分3种簇分定义,其研究结果表明,加入分层的识别方案的密码算法识别效果更佳。Arvind等[7]提出了一种利用位平面图像特征和模糊决策准则的方法,实现了识别和隔离用相同密钥加密的图像。但是,目前密码算法识别方案仍然存在以下3个问题:
1)识别方案大多基于经典的单一分类器模型。de Mello等[8]使用单一的支持向量机分类器识别方案对密码算法进行识别;Sharif等[9]比较了在分组密码体制识别过程中不同分类模型的识别效果,认为Rotation Forest模型效果更好。
2)识别方案稳定性不好。Fan等[10]使用随机森林、逻辑回归和支持向量机3种分类模型对8种分组密码体制开展识别任务。但以决策树和支持向量机为例,单一的决策树分类器在处理分类问题时由于数据集中存在噪声或随机错误,容易出现过拟合的状况,导致分类结果只能达到局部最优;而支持向量机分类器虽然泛化能力强,但其训练代价较大,参数的调整和核函数的选择都会极大地影响分类结果;赵志诚等[11]提出了基于随机性检测的密码算法识别方案,最高识别准确率可达80%以上,证明了随机性检测可有效地提取密文特征,但其方案相对复杂,且随着分类对象的改变,所需的最优特征不断改变,需要提前分别训练不同类别特征以此得到最优特征,效率较低。
3)识别方案涉及因素较为单一,仅考虑加密模式对密码算法识别效果的影响是不全面的。如丁伟等[12]对5种分组密码算法进行两两识别,提出了在训练和测试过程中所使用的密钥是否相同会对识别准确率有一定的影响。
为解决以上问题,本文基于集成学习思想提出一种混合梯度提升决策树和逻辑回归(hybrid gradient boosting decision tree and logistic regression,HGBDTLR)模型,并基于该模型构造出一种分组密码算法识别方案(block cipher algorithm identification scheme based on HGBDTLR model,HGLBIS),旨在提高密码算法识别的准确率与稳定性。
1. 基础知识
1.1 密码算法识别原理
目前,密码算法识别方案的设计思想主要来源于统计方法和机器学习技术。不同的密码算法进行加密产生的密文空间都存在一定的差异,由此可以提取出刻画相应差异的特征,作为密码算法识别的基础[5]。
密码算法识别的任务是区分这些具有细小差异的特征,从而识别出特定的密文对应的密码算法。由于密码学的不断发展,各种密码算法不断增多,各种特征之间存在着更为复杂与细微的差异,所以目前更多的是使用设计简单、性能稳定、能够处理复杂数据关系的基于机器学习的密码算法识别方案。
下文给出密码算法识别的基本要素:密文、密文特征、密码算法识别和密码算法识别方案的形式化定义。
定义1(密文) 设密码算法集合
$ A = \{ {a_1},{a_2}, \cdots ,{a_k}{\text{\} }} $ ,其中,$ k $ 为密码算法的数量。对于任意给定的密码算法
$ {a_i} \in A $ ,其加密生成的密文文件为:$$ C = \{ {b_1},{b_2}, \cdots ,{b_m}\} $$ (1) 式中,
$ {b_t} $ 为密文文件的第t($ 1 \le t \le m $ )个字符,且可表示为不同类型的字符,如已有研究多将密文表示为以比特或字节为基本字符的有序集合[3-7]。定义2(密文特征) 对密文文件
$ C $ 进行特征提取,得到维数为$ d $ 的特征,即:$$ {F_{{\rm{fea}}}} = \{ {x_1},{x_2},\cdots,{x_d}\} $$ (2) 式中,
${F_{{\rm{fea}}}}$ 为使用某种特征提取的计算方法对密文数据$ C $ 所提取的d维特征。定义3(密码算法识别) 对密码算法集合
$ A $ ,密文文件$ C $ ,在密码算法$ {a_i} $ $ ({a_i} \in A) $ 未知的情况下,利用某一识别方案$ J $ 进行唯密文破解,并以一定的准确率识别出其密码算法$ {a_i} $ 的过程,称为密码算法识别,记为三元组,即:$$ R = (A,J,{h_{{\text{J}}}}) $$ (3) 式中,准确率
$ {h_{{\text{J}}}} $ 被认为是对评价密码算法辨认技术和识别方案的自然度量。定义4(密码算法识别方案) 在密码算法识别
$R = (A,J,{h_{{\text{J}}}})$ 中,密码算法识别方案用三元组表示:$$ P = ({O_{{\text{oper}}}},{F _{\rm fea}},{M_{{\text{RA}}}}) $$ (4) 式中:
$ {O_{{\text{oper}}}} $ 为直接对具体密码算法进行识别的工作流程;${F_{{\rm{fea}}}}$ 为对密文文件$ F $ 进行特征提取得到的一组特征;$ {M_{{\text{RA}}}} $ 为密码算法识别方案$ P $ 采用的识别模型,在本文中即为HGBDTLR模型。其工作流程如图1所示。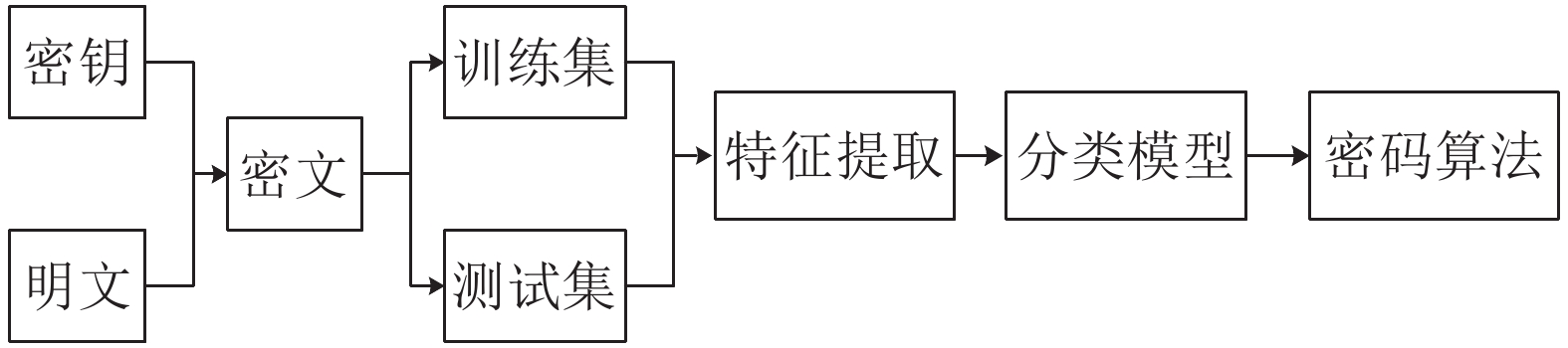 图 1 密码算法识别工作流程Fig. 1 Workflow of cryptographic algorithm identification
图 1 密码算法识别工作流程Fig. 1 Workflow of cryptographic algorithm identification 下载:
全尺寸图片
下载:
全尺寸图片
1.2 密文特征提取
在机器学习领域,特征的选择将直接影响分类器的识别结果[13]。对密文进行随机性检测是评判密码算法是否安全的一个重要标准,文献[6,11]中均采用随机性检测提取密文特征且具有较好的效果,说明随机性检测能够反映密文中存在的差异。
在常用的随机性检测标准中,美国国家标准与技术研究所(National Institute of Standards and Technology,NIST)制定的SP 800–22[14]标准,具有较广泛的检测覆盖率,对密文序列各个方面和序列分段方式都有全面且针对性的测试方法,受到许多研究人员的青睐。
依照现有研究及NIST随机性检测要求,对定义2进行扩充,给出定义5。
定义 5(基于NIST随机性检测提取密文特征) 密文特征可表示为四元组:
$$ {F_{{\text{fea}}}} = ({D_{{\text{DR}}}},{O_{{\text{orga}}}},{T_{{\text{NIST}}}},d) $$ (5) 式中,
$ {T_{{\text{NIST}}}} = \{ {T_{{\text{NIST\_1}}}},{T_{{\text{NIST\_2}}}}, \cdots ,{T_{{\text{NIST\_15}}}}\} $ ,包含15种不同的随机性测试程序;$ {D_{{\text{DR}}}} $ 为密文数据的表示方式;$ {O_{{\text{orga}}}} $ 为测试文件$ {T_{{\text{NIST\_}}i}} $ 中要求的以密文分块、各块内相同位置组合、不同类型字符组合为例的密文数据组织方式;$ d $ 为特征维数。1.3 梯度提升决策树模型
梯度提升决策树(gradient boosting decision tree,GBDT)模型[15-16]是一种应用很广泛的机器学习模型,可以用于分类与回归。该模型通过Boosting方式逐步构建一系列单个决策树,再进行多轮迭代,每轮迭代产生一个弱分类器,而每个分类器在上一轮分类器的残差基础上进行训练。由多棵决策树组成,所有树的结论累加起来作为最终结果。该模型能灵活地处理多个变量和目标之间的非线性关系,且拥有较高的预测准确度。当使用损失函数健壮时,模型鲁棒性非常强,受异常值影响小。
1.4 逻辑回归模型
逻辑回归(logistic regression,LR)模型是一种形式简单,可解释性好的机器学习模型。该模型通过在线性回归的基础上增加一个sigmoid函数(非线形)映射,使其成为一个优秀的分类算法。其计算代价不高,易于理解和实现,并且分类时计算量非常小,速度很快,存储资源低。
2. HGLBIS方案
本文基于HGBDTLR模型构造分类器,进而提出HGLBIS方案,所提的HGLBIS方案分为训练和测试两个阶段。
2.1 HGBDTLR模型
基于若干弱分类器组合成的集成学习模型在分类问题上稳定性更强、识别效率更高、参数设置更灵活[17-19];其Stacking的自动化集成策略既可有效对抗过拟合问题,又可有效提升单一分类器的泛化能力和鲁棒性[20]。许多研究表明,集成学习分类器比单一的分类器拥有更好的预测性能,并已在许多不同的问题场景得到广泛应用[21-22]。
相较于传统的分类模型,GBDT模型虽然能灵活地处理各种类型的数据,包括连续值和离散值,且鲁棒性较强,但是该模型的分类效率受参数设置影响较大,不合适的参数设置会导致模型更加复杂,进而使模型陷入过拟合;LR模型虽然简单且易于实现,但其容易欠拟合,一般准确度不太高,不能很好地处理大量多类特征或变量。针对该问题,本文基于集成学习思想提出混合梯度决策树和逻辑回归模型,简称HGBDTLR模型。下面详细介绍HGBDTLR模型的框架和具体算法流程。
2.1.1 HGBDTLR模型的框架
HGBDTLR模型的主要思想是集成学习中的叠加法,将多个基分类器分布在多层上,每一层分类器的预测结果作为下一层的输入,以此类推,通过多层训练实现集成,从而得到最终的分类预测结果。HGBDTLR模型是将GBDT模型和LR模型进行集成,首先,用原始10组特征训练GBDT模型;然后,利用GBDT模型学习到的树来构造新特征;之后,将新特征做one-hot编码;最后,将这些新特征加入到原有特征中,用这11组特征训练LR模型,并进行预测。
2.1.2 HGBDTLR模型的算法流程
HGBDTLR模型的具体算法流程如算法所示。
算 法 HGBDTLR模型算法
输入:含标签的训练集
$D = \{ ({d_1},{l_1}),({d_2},{l_2}), \cdots , ({d_N},{l_N}) \}$ ;回归树的个数$ M $ ;损失函数为$ L(y,f(x)) $ 。输出:集成分类器模型
${ \rm HGBDTLR} $ 。01. 输入初始化样本
$ D $ ;02. 有放回的地随机抽样得到样本
$ {D^*} $ ;03. 初始化预测结果
${f_0}(x) = \mathop {\rm{arg min}}\limits_c \displaystyle\sum\limits_{i = 1}^N {L({y_i},c)} \text{;} $ 04. for
$ m = 1 $ to$ M $ do05. for
$ i = 1 $ to$ N $ do06.
${r_{mi}} = - {\left[ {\dfrac{{\partial L({y_i},f({x_i}))}}{{\partial f({x_i})}}} \right]_{f(x) = {f_{m - 1}}(x)}}$ ;07. 对
$ {r_{mi}} $ 拟合一棵回归树,估计叶节点区域$ {R_{mj}} $ ,进而拟合残差$ {c_{mj}} $ ;08. end
09. for
$ j = 1 $ to$ {J_m}{\text{ }} $ do10.
${c_{mj}} = \mathop {{\text{argmin}}}\limits_c \displaystyle\sum\limits_{{x_i} \in {R_{mj}}} {L({y_i},{f_{m - 1}}({x_i}) + c)}$ ;11. 更新回归树
${f_m}(x) = {f_{m - 1}}(x) + \displaystyle\sum\limits_{j = 1}^{{J_m}} {{c_{mj}}I(x \in {R_{mj}})} \text{;}$ 12. end
13. end
14. 由
$ M $ 棵回归树组成梯度提升决策树模型,作为stacking的第1阶段基分类器$ h'(x) $ ;15. 将
$ h'(x) $ 的预测结果作为新特征加入初始化数据集$ D $ ,生成新数据集$ D' $ ;16. 对
$ D' $ 进行one-hot编码处理;17. for
$ i = 1 $ to$ m $ 遍历$ D' $ do18. 计算样本
$ i $ 的权重;19. 计算样本
$ i $ 的梯度;20. 更新回归系数,确定sigmoid函数;
21. end
22. 输出集成分类器
$ h(x) $ ,即HGBDTLR分类器模型。2.2 HGLBIS方案
基于HGBDTLR模型构造HGLBIS密码算法识别方案,该方案可分为密文特征提取和密码算法识别分类器的构造两个主要部分。1)密文特征提取。基于第1.2节定义5给出的NIST随机性检测提取密文特征,总共得到15种特征,选定有意义的10种作为分类需要的密文特征。2)密码算法识别分类器的构造。基于第2.1.1节提出的HGBDTLR模型框架,使用第2.1.2节给出的HGBDTLR模型算法构造密码算法识别分类器。HGLBIS方案以提取到的各类密文特征数据作为分类器的输入,经过数据的训练与测试阶段,从而完成对具体密码算法地识别。基于HGLBIS方案的识别流程如图2所示。
 图 2 HGLBIS方案识别流程Fig. 2 Identification process based on HGLBIS下载:
全尺寸图片
图 2 HGLBIS方案识别流程Fig. 2 Identification process based on HGLBIS下载:
全尺寸图片
选取定义4的密码算法识别方案
$P = ({O_{{\rm{oper}}}},{F_{{\rm{fea}}}}, {\rm{HGBDTLR}})$ ,其中,$ {\text{HGBDTLR}} $ 表示本文方案采用的识别模型,即混合梯度提升决策树和逻辑回归模型,基于该模型构造的HGLBIS密码算法识别方案工作流程如下,分为训练和测试两个部分。1)训练阶段包括如下8个步骤:
输入:密码算法已知的一组测试密文文件
$ C = \left\{ {{C_1},{C_2}, \cdots ,{C_n}} \right\} $ ,其中,$ n = k \times F $ ,$ k $ 为密码算法集合$ A = \left\{ {{a_1},{a_2}, \cdots ,{a_k}} \right\} $ 中的密码算法数量,$ F $ 为每种密码算法加密的密文数量。输出:训练好的HGBDTLR模型。
①输入总共
$ n $ 个密文文件,根据文献[8]中的随机性检测方法对每一个密文文件提取特征,得到$ n $ 组密文特征集$ {S _{\rm featr}} = \{ s_i^j|i = 1,2, \cdots ,n,j = 1,2, \cdots ,d\} $ ,其中$ s_i^j $ 为第$ i $ 个训练密文文件的第$ j $ 个特征。②将特征集和密文标签组成样本二元组
$({S _{{\rm{featr}}}}, {L_{{\rm{lab}}}})$ 作为原始数据集,记为$ T $ 。③以十折重复随机子抽样挑选
$ T $ 中的75%用于进行有监督学习,记为$ {T_{\rm tr}} $ ,另外25%用于验证训练得到的模型性能,记为$ {T_{\rm te}} $ 。④输入特征集
$ {T_{\rm tr}} $ ,共有$ n \times 75{\text{% }} $ 个密文文件,每个密文文件表示一个样本,每个样本有$ d $ 个特征。⑤输入回归树的个数
$ M $ 。⑥使用GBDT算法默认的损失函数
$L(y,f(x)){\text{ = }} {\left( {y - f\left( x \right)} \right)^2}$ 作为第2.1.2节给出的HGBDTLR算法的输入损失函数,从而训练出一个HGBDTLR分类模型。⑦将特征集
$ {T_{\rm te}} $ 输入到训练好的模型中进行预测,并将预测结果与原始标签进行比较,得到模型识别准确率,从而对模型性能进行评判。⑧修改步骤⑤中回归树的个数,重复步骤⑤~⑦,直至找到能使准确率达到最高的模型,即为最终训练好的HGBDTLR模型。
2)测试阶段包括如下2个步骤:
输入:密码算法未知的一组测试密文文件
${C_{\rm cf}} = \{ { {{C_{{\rm cf}\_i}}} |i = 1,2, \cdots ,n} \}$ ,其中$ n $ 为待测密文文件的个数。输出:待测密文文件分类结果即加密使用的密码算法
${A_{\rm at}} = \{ { {{A_{{\rm at}\_i}}} |{A_{{\rm at}\_i}} \in A,i = 1,2, \cdots ,n} \}$ 。①对待识别密文文件
$ {C_{{\rm cf}\_1}},{C_{{\rm cf}\_2}}, \cdots ,{C_{{\rm cf}\_n}} $ 的内容进行特征提取,得到密文特征${S _{\rm feate}} = \{ s_i^j|i = 1,2, \cdots , n,j = 1,2, \cdots ,d\}$ 。②将密文特征
${S _{{\rm{feate}}}}$ 输入到已训练好的HGBDTLR分类模型中,输出识别结果,即与该密文对应的密码算法标签$ {A_{\rm at}} $ 。3. 实验环境
3.1 数据准备
在由Python编写的开源工具sp800_22_tests-master基础上进行改进以实现密文特征提取。主程序负责从磁盘读取密文文件,每种随机性检测算法被封装成一个子模块,各子模块间相互独立,互不干扰,特征提取时各模块并行执行,并将结果保存到不同的文件中。
实验选择用Python的Crypto密码算法库进行加密。所用的明文是通过Python的Crypto加密模块使用Fortuna Accumulator方法生成的随机数据,明文文件大小为1、8、64、256和512 kB的500个文件。加密密钥和初始化向量使用Crypto的Cipher加密模块生成。密文由AES、3DES、Blowfish、CAST和RC2这5种分组密码算法的ECB模式和固定16位字符串密钥加密生成。使用这5种分组密码算法分别对5种不同大小的明文进行加密,每种密码算法加密的密文样本量均为500份,总共产生2 500个密文文件。利用NIST随机性测试程序中的15种随机性测试方法对2 500个密文文件分别进行特征提取,并选定有意义的10种特征值作为输入分类器的实验数据。对该实验数据进行重复随机子抽样验证,随机抽取75%的样本作为训练集,其余25%作为测试集,用于后文对5种密码算法的二分类与五分类识别实验。5种密码算法具体参数如表1所示。
表 1 5种分组密码算法的具体参数Table 1 Specific parameters of five block cipher algorithms标记 结构 密钥 工作模式 参数
规模实现
方式AES SP 选定 ECB 固定
参数Crypto 3DES Feistel 选定 ECB 固定
参数Crypto Blowfish Feistel 选定 ECB 固定
参数Crypto CAST Feistel 选定 ECB 固定
参数Crypto RC2 Feistel 选定 ECB 固定
参数Crypto 3.2 分类结果评价标准
本文采用准确率、查准率、查全率、F1度量、“受试者工作特征”曲线(receiver operating characteristic curve,ROC)与ROC曲线下的面积(area under roc curve,AUC)作为评价方案识别效果好坏的标准。
利用混淆矩阵得到以上标准对应的数值或图象,混淆矩阵共产生4种结果,即真阳性、真阴性、假阳性和假阴性。令XTP、XTN、XFP、XFN分别表示其对应的样本数,式(6)~(8)分别用于计算方案的准确率、查准率、查全率:
$$ {Y_{{\text{Accuracy}}}} = \frac{{{X_{{\text{TP}}}} + {X_{{\text{TN}}}}}}{{{X_{{\text{TP}}}} + {X_{{\text{TN}}}} + {X_{{\text{FP}}}} + {X_{{\text{FN}}}}}} $$ (6) $$ {Y_{{\text{Precision}}}} = \frac{{{X_{{\text{TP}}}}}}{{{X_{{\text{TP}}}} + {X_{{\text{FP}}}}}} $$ (7) $$ {Y_{{\text{Recall}}}} = \frac{{{X_{{\text{TP}}}}}}{{{X_{{\text{TP}}}} + {X_{{\text{FN}}}}}} $$ (8) 式中:
$ {Y_{{\text{Accuracy}}}} $ 为分类模型所有判断正确的结果占总观测值的比重,即真阳性与真阴性所占总观测值的比重;$ {Y_{{\text{Precision}}}} $ 为在预测模型是阳性的所有结果中真阳性所占的比重;$ {Y_{{\text{Recall}}}} $ 为在真实值是阳性的所有结果中真阳性所占的比重。查准率和查全率是一对矛盾的度量,一般来说,查准率高时,查全率偏低;查全率高时,查准率偏低。为了平衡查准率和查全率,使用查准率和查全率的调和平均数$ {F_1} $ 度量评价分类器的性能,如式(9)所示:$$ {F_1}_{} = \frac{{2{X_{{\text{TP}}}}}}{{2{X_{{\text{TP}}}} + {X_{{\text{FP}}}} + {X_{{\text{PN}}}}}} $$ (9) ROC曲线以假阳性率为横坐标,真阳性率为纵坐标生成,当正负样本的分布发生变化时,其形状能够基本保持不变,因此,该评估指标能降低不同测试集带来的干扰,更加客观地衡量模型本身的性能。根据ROC曲线位置,将整幅图划分成了两部分,曲线下方部分的面积被称为AUC,用于表示预测准确性,AUC值越高,也就是曲线下方面积越大,说明预测准确率越高。
4. 实验结果与分析
从准确率、查准率、查全率、
$ {F_1} $ 度量、ROC曲线和AUC值6个方面开展识别实验。其中,预测模型建立在利用文献[11]给出的特征提取方法提取的10个特征的基础上。4.1 密码算法二分类识别
本文基于十折重复随机子抽样,首先,使用8种分类模型,即支持向量机[2](support vector machines,SVM)、随机森林[11](random forest,RF)、高斯朴素贝叶斯[23](Gaussian naive Bayes,GNB)、决策树[24](decision tree,DT)、K-近邻[1](K-neighbors,KNN)、AdaBoost[23]、GBDT[25]和LR[26]分别构造8种分组密码算法识别方案,即SVMBIS方案、RFBIS方案、GNBBIS方案、DTBIS方案、KNNBIS方案、ABBIS方案、GBDTBIS方案和LRBIS方案,作为与本文提出的HGBDTLR模型所构造的HGLBIS方案的对比方案;然后,选择5种分组密码算法中最典型的2种AES和3DES加密算法加密的5种不同大小(1、8、64、256和512 kB)的密文文件进行二分类测试,结果如表2所示。
表 2 9种分组密码算法识别方案二分类识别结果Table 2 Binary classification identification results of nine block cipher algorithm identification schemes评估指标 文件大小/kB 分类器 SVMBIS
方案RFBIS
方案GNBBIS
方案DTBIS
方案KNNBIS
方案ABBIS
方案GBDTBIS
方案LRBIS
方案HGLBIS
方案准确率/% 1 35.0 40.0 47.5 40.0 40.0 37.5 47.5 42.5 67.5 8 37.5 47.5 55.0 45.0 45.0 47.5 52.5 45.0 70.0 64 60.0 56.0 64.0 42.0 46.0 44.0 48.0 56.0 67.5 256 40.0 50.0 42.5 57.5 50.0 35.0 47.5 42.5 70.0 512 50.0 55.0 47.5 50.0 50.0 55.0 52.5 50.0 65.0 查准率/% 1 35.7 40.9 48.2 40.9 40.0 37.8 49.6 43.6 67.4 8 38.2 49.1 55.5 45.9 44.4 48.2 53.9 45.9 72.8 64 62.7 57.6 65.9 42.3 47.9 45.6 49.9 58.4 69.8 256 40.9 53.0 43.5 60.1 51.0 35.2 48.7 43.7 70.2 512 50.0 55.0 47.8 49.5 50.0 0. 55 51.8 50.0 64.8 查全率/% 1 35.0 40.0 47.5 40.0 40.0 37.5 47.5 42.5 67.5 8 37.5 47.5 55.0 45.0 45.0 47.5 52.5 45.0 70.0 64 60.0 56.0 64.0 42.0 46.0 44.0 48.0 56.0 67.5 256 40.0 50.0 42.5 57.5 50.0 35.0 47.5 42.5 70.0 512 50.0 55.0 47.5 50.0 50.0 55.0 52.5 50.0 65.0 $ {F_1} $度量/% 1 35.0 40.0 47.5 40.0 40.0 37.5 47.5 42.5 67.5 8 37.5 47.5 55.0 45.0 45.0 47.5 52.5 45.0 70.0 64 60.0 56.0 64.0 42.0 46.0 44.0 48.0 56.0 67.5 256 40.0 50.0 42.5 57.5 50.0 35.0 47.5 42.5 70.0 512 kB 50.0 55.0 47.5 50.0 50.0 55.0 52.5 50.0 65.0 由表2可以看出:在同一密文大小文件下,本文所提的HGLBIS方案的识别准确率均显著高于其他8种单一分类方案。在512 kB大小的密文文件上,HGLBIS方案的准确率相对较低为65%,相较于单一GBDTBIS方案52.5%的识别准确率提升了12.5%,相较于单一LRBIS方案50%的识别准确率提升了15%。在8和256 kB的密文文件上,HGLBIS方案的识别准确率高达70%,相较于单一GBDTBIS方案52.5%和47.5%的识别准确率提升了17.5%和22.5%,相较于单一LRBIS方案45%和42.5%的识别准确率提升了25%和27.5%。通过比较9种分类方案的查准率,查全率以及
$ {F_1} $ 度量,可以发现,在密文文件大小相同的情况下,本文所提的HGLBIS方案的这3种指标同样高于其他8种单一分类方案,进一步说明了HGLBIS方案分类效果最好。为更直观地表现不同方案之间的识别结果的差异,将二分类识别中9种分类方案在5种大小的密文下的识别准确率以2维折线图展示,如图3所示。由图3可以看出:经典分类方案的识别准确率较低,基本维持在30%~60%之间波动;而本文提出的HGLBIS方案具有最高的识别准确率,并且不低于65%;同时,随着密文长度的变化,识别准确率曲线呈波动性变化,说明密文文件大小对识别准确率具有一定的影响,但相较于其他8种分类方案,本文提出的HGLBIS方案的识别准确率波动性最小,基本不受文件大小的影响,即HGLBIS方案具有更强的稳定性。
 图 3 二分类识别中9种分类方案在5种大小密文文件下的识别准确率Fig. 3 Identification accuracy of nine classification schemes in binary classification under five sizes of ciphertext files下载:
全尺寸图片
图 3 二分类识别中9种分类方案在5种大小密文文件下的识别准确率Fig. 3 Identification accuracy of nine classification schemes in binary classification under five sizes of ciphertext files下载:
全尺寸图片
9种分类方案对5种大小的密文在AES和3DES二分类识别中的接受者操作特性ROC曲线如图4所示。由图4可知:密文文件大小不同,得到的分类模型结果不同,除了64 kB以外的其他4种文件大小情况下,本文所提的HGLBIS方案的ROC曲线显著靠近左上角,其AUC值最高,并且能够将其他8种方案的曲线完全包含起来,表明HGLBIS方案的分类效果最好。对于密文文件大小为64 kB的ROC曲线,除了SVMBIS和LRBIS方案外,HGLBIS方案同样具有最高的AUC值;SVMBIS和LRBIS方案的AUC值也与本文所提的HGLBIS方案基本相近。表明HGLBIS方案在绝大多数情况下均具有最高的识别准确率,只有在极少数情况下优势无法体现。
 图 4 9种分类方案对5种大小的密文在AES和3DES二分类识别中的ROC曲线Fig. 4 ROC curves of nine classification schemes for five sizes of ciphertext in AES and 3DES下载:
全尺寸图片
图 4 9种分类方案对5种大小的密文在AES和3DES二分类识别中的ROC曲线Fig. 4 ROC curves of nine classification schemes for five sizes of ciphertext in AES and 3DES下载:
全尺寸图片
4.2 密码算法五分类识别
使用9种分组密码算法识别方案对AES、3DES、Blowfish、CAST和RC2这5种分组密码算法加密得到5种不同大小的密文文件,在9种分类方案上进行五分类实验,其识别结果如表3所示。
表 3 9种分组密码算法识别方案五分类识别结果Table 3 Five classification identification results of nine block cipher algorithm identification schemes评估指标 文件大小/kB 分类器 SVMBIS
方案RFBIS
方案GNBBIS
方案DTBIS
方案KNNBIS
方案ABBIS
方案GBDTBIS
方案LRBIS
方案HGLBIS
方案准确率/% 1 17.6 25.0 26.4 25.6 19.2 25.6 27.2 25.6 32.0 8 17.6 22.4 20.8 20.0 19.2 15.2 14.4 18.4 29.0 64 15.2 16.8 17.6 22.4 24.0 12.0 15.2 16.0 28.0 256 18.4 19.2 13.6 22.4 21.6 21.6 18.4 16.8 30.0 512 31.0 24.0 17.0 20.0 17.0 21.0 24.0 19.0 28.0 查准率/% 1 13.9 27.3 24.9 28.9 16.2 30.1 27.5 21.1 33.3 8 20.0 28.6 24.4 21.6 26.2 21.2 17.2 24.0 30.3 64 14.4 17.5 19.3 28.0 26.4 13.4 19.4 14.7 29.2 256 18.4 20.8 13.4 25.1 21.0 24.7 18.6 19.0 30.9 512 31.5 26.5 17.6 25.7 19.6 20.0 27.3 19.9 28.3 查全率/% 1 17.6 25.0 26.4 25.6 19.2 25.6 27.2 25.6 32.0 8 17.6 22.4 20.8 20.0 19.2 15.2 14.4 18.4 29.0 64 15.2 16.8 17.6 22.4 24.0 12.0 15.2 16.0 28.0 256 18.4 19.2 13.6 22.4 21.6 21.6 18.4 16.8 30.0 512 31.0 24.0 17.0 20.0 17.0 21.0 24.0 19.0 28.0 $ {F_1} $度量/% 1 17.6 25.0 26.4 25.6 19.2 25.6 27.2 25.6 32.0 8 17.6 22.4 20.8 20.0 19.2 15.2 14.4 18.4 29.0 64 15.2 16.8 17.6 22.4 24.0 12.0 15.2 16.0 28.0 256 18.4 19.2 13.6 22.4 21.6 21.6 18.4 16.8 30.0 512 31.0 24.0 17.0 20.0 17.0 21.0 24.0 19.0 28.0 由表3可知:相比于其他8种分类方案,在密文文件大小相同的情况下,本文提出的HGLBIS方案的识别准确率仅在文件大小为512 kB时比SVMBIS方案的识别准确率略低3%,在另外4种文件大小时均高于其他分类方案。HGLBIS方案的识别准确率在30%左右波动(最高为32%,最低为28%),高于其他方案多在20%左右波动的识别准确率,也高于随机猜测20%的识别准确率。查准率、查全率和
$ {F_1} $ 度量与准确率具有相似的规律,仅在文件大小为512 kB时比SVMBIS方案的3种指标值略低,进一步说明HGLBIS分类方案在绝大多数情况下分类效果最好。总体来说,本文提出的HGLBIS分类方案的分类效果最优。同时,随着密文文件大小的变化,9种方案的识别率呈波动变化,其中,HGLBIS分类方案波动幅度最小,模型稳定性最高。5. 结 论
本文基于集成学习的思想提出了一种混合梯度提升决策树和逻辑回归(HGBDTLR)模型,并在此基础上提出了一种基于集成学习的分组密码算法识别方案HGLBIS。实验结果表明:基于集成学习的密码算法识别方案与传统的密码算法识别方案相比,在分类问题上有更强的稳定性、更高的识别效率,能在一定程度上改善密码算法识别工作中因密码算法数量的增多、密文数据复杂化以及数据间干扰的增加,导致的识别准确率及识别稳定性变差等问题。
但是,本方案在极个别情况下相对于单一识别方案识别效果不佳,在包含分组密码、公钥密码体制场景下的识别效果等方面,仍有进一步思考与实验之处。在下一步研究工作中,将考虑加入如RSA、ElGamal、ECC等经典公钥密码作为实验对象,扩展应用场景,同时,尝试从不同的分类算法内部结构入手,进一步提升所提方案的识别准确率和稳定性。总之,基于集成学习的密码算法识别方案作为一种新思路,值得进一步探索,对未来密码算法识别工作具有积极意义。
-
图 1 密码算法识别工作流程
Fig. 1 Workflow of cryptographic algorithm identification
下载:
全尺寸图片
图 2 HGLBIS方案识别流程
Fig. 2 Identification process based on HGLBIS
下载:
全尺寸图片
图 3 二分类识别中9种分类方案在5种大小密文文件下的识别准确率
Fig. 3 Identification accuracy of nine classification schemes in binary classification under five sizes of ciphertext files
下载:
全尺寸图片
图 4 9种分类方案对5种大小的密文在AES和3DES二分类识别中的ROC曲线
Fig. 4 ROC curves of nine classification schemes for five sizes of ciphertext in AES and 3DES
下载:
全尺寸图片
表 1 5种分组密码算法的具体参数
Table 1 Specific parameters of five block cipher algorithms
标记 结构 密钥 工作模式 参数
规模实现
方式AES SP 选定 ECB 固定
参数Crypto 3DES Feistel 选定 ECB 固定
参数Crypto Blowfish Feistel 选定 ECB 固定
参数Crypto CAST Feistel 选定 ECB 固定
参数Crypto RC2 Feistel 选定 ECB 固定
参数Crypto 表 2 9种分组密码算法识别方案二分类识别结果
Table 2 Binary classification identification results of nine block cipher algorithm identification schemes
评估指标 文件大小/kB 分类器 SVMBIS
方案RFBIS
方案GNBBIS
方案DTBIS
方案KNNBIS
方案ABBIS
方案GBDTBIS
方案LRBIS
方案HGLBIS
方案准确率/% 1 35.0 40.0 47.5 40.0 40.0 37.5 47.5 42.5 67.5 8 37.5 47.5 55.0 45.0 45.0 47.5 52.5 45.0 70.0 64 60.0 56.0 64.0 42.0 46.0 44.0 48.0 56.0 67.5 256 40.0 50.0 42.5 57.5 50.0 35.0 47.5 42.5 70.0 512 50.0 55.0 47.5 50.0 50.0 55.0 52.5 50.0 65.0 查准率/% 1 35.7 40.9 48.2 40.9 40.0 37.8 49.6 43.6 67.4 8 38.2 49.1 55.5 45.9 44.4 48.2 53.9 45.9 72.8 64 62.7 57.6 65.9 42.3 47.9 45.6 49.9 58.4 69.8 256 40.9 53.0 43.5 60.1 51.0 35.2 48.7 43.7 70.2 512 50.0 55.0 47.8 49.5 50.0 0. 55 51.8 50.0 64.8 查全率/% 1 35.0 40.0 47.5 40.0 40.0 37.5 47.5 42.5 67.5 8 37.5 47.5 55.0 45.0 45.0 47.5 52.5 45.0 70.0 64 60.0 56.0 64.0 42.0 46.0 44.0 48.0 56.0 67.5 256 40.0 50.0 42.5 57.5 50.0 35.0 47.5 42.5 70.0 512 50.0 55.0 47.5 50.0 50.0 55.0 52.5 50.0 65.0 $ {F_1} $度量/% 1 35.0 40.0 47.5 40.0 40.0 37.5 47.5 42.5 67.5 8 37.5 47.5 55.0 45.0 45.0 47.5 52.5 45.0 70.0 64 60.0 56.0 64.0 42.0 46.0 44.0 48.0 56.0 67.5 256 40.0 50.0 42.5 57.5 50.0 35.0 47.5 42.5 70.0 512 kB 50.0 55.0 47.5 50.0 50.0 55.0 52.5 50.0 65.0 表 3 9种分组密码算法识别方案五分类识别结果
Table 3 Five classification identification results of nine block cipher algorithm identification schemes
评估指标 文件大小/kB 分类器 SVMBIS
方案RFBIS
方案GNBBIS
方案DTBIS
方案KNNBIS
方案ABBIS
方案GBDTBIS
方案LRBIS
方案HGLBIS
方案准确率/% 1 17.6 25.0 26.4 25.6 19.2 25.6 27.2 25.6 32.0 8 17.6 22.4 20.8 20.0 19.2 15.2 14.4 18.4 29.0 64 15.2 16.8 17.6 22.4 24.0 12.0 15.2 16.0 28.0 256 18.4 19.2 13.6 22.4 21.6 21.6 18.4 16.8 30.0 512 31.0 24.0 17.0 20.0 17.0 21.0 24.0 19.0 28.0 查准率/% 1 13.9 27.3 24.9 28.9 16.2 30.1 27.5 21.1 33.3 8 20.0 28.6 24.4 21.6 26.2 21.2 17.2 24.0 30.3 64 14.4 17.5 19.3 28.0 26.4 13.4 19.4 14.7 29.2 256 18.4 20.8 13.4 25.1 21.0 24.7 18.6 19.0 30.9 512 31.5 26.5 17.6 25.7 19.6 20.0 27.3 19.9 28.3 查全率/% 1 17.6 25.0 26.4 25.6 19.2 25.6 27.2 25.6 32.0 8 17.6 22.4 20.8 20.0 19.2 15.2 14.4 18.4 29.0 64 15.2 16.8 17.6 22.4 24.0 12.0 15.2 16.0 28.0 256 18.4 19.2 13.6 22.4 21.6 21.6 18.4 16.8 30.0 512 31.0 24.0 17.0 20.0 17.0 21.0 24.0 19.0 28.0 $ {F_1} $度量/% 1 17.6 25.0 26.4 25.6 19.2 25.6 27.2 25.6 32.0 8 17.6 22.4 20.8 20.0 19.2 15.2 14.4 18.4 29.0 64 15.2 16.8 17.6 22.4 24.0 12.0 15.2 16.0 28.0 256 18.4 19.2 13.6 22.4 21.6 21.6 18.4 16.8 30.0 512 31.0 24.0 17.0 20.0 17.0 21.0 24.0 19.0 28.0 -
[1] 赵志诚.基于机器学习的密码体制识别研究[D].郑州:战略支援部队信息工程大学,2018. Zhao Zhicheng.The research of cryptosystem recognition scheme based on machine learning[D].Zhengzhou:Information Engineering University,2018. [2] Dileep A D,Sekhar C C.Identification of block ciphers using support vector machines[C]//Proceedings of the 2006 IEEE International Joint Conference on Neural Network Proceedings.Vancouver:IEEE,2006:2696–2701. [3] de Mello F L,Xexéo J A M.Identifying encryption algorithms in ECB and CBC modes using computational intelligence[J].Journal of Universal Computer Science,2018,24(1):25–42. doi: 10.3217/jucs-024-01-0025 [4] de Souza W A R,Tomlinson A.A distinguishing attack with a neural network[C]//Proceedings of the 2013 IEEE 13th International Conference on Data Mining Workshops.Dallas:IEEE,2013:154–161. [5] 吴杨,王韬,邢萌,等.基于密文随机性度量值分布特征的分组密码算法识别方案[J].通信学报,2015,36(4):146–155. doi: 10.11959/j.issn.1000-436x.2015107 Wu Yang,Wang Tao,Xing Meng,et al.Block ciphers identification scheme based on the distribution character of randomness test values of ciphertext[J].Journal on Communications,2015,36(4):146–155 doi: 10.11959/j.issn.1000-436x.2015107 [6] 黄良韬,赵志诚,赵亚群.基于随机森林的密码体制分层识别方案[J].计算机学报,2018,41(2):382–399. doi: 10.11897/SP.J.1016.2018.00382 Huang Liangtao,Zhao Zhicheng,Zhao Yaqun.A two-stage cryptosystem recognition scheme based on random forest[J].Chinese Journal of Computers,2018,41(2):382–399 doi: 10.11897/SP.J.1016.2018.00382 [7] Arvind,Ratan R.Identifying traffic of same keys in cryptographic communications using fuzzy decision criteria and bit-plane measures[J].International Journal of System Assurance Engineering and Management,2020,11(2):466–480. doi: 10.1007/s13198-019-00878-7 [8] Luis de Mello F,Antonio Moreira Xexeo J.Cryptographic algorithm identification using machine learning and massive processing[J].IEEE Latin America Transactions,2016,14(11):4585–4590. doi: 10.1109/TLA.2016.7795833 [9] Sharif S O,Kuncheva L I,Mansoor S P.Classifying encryption algorithms using pattern recognition techniques[C]//Proceedings of the 2010 IEEE International Conference on Information Theory and Information Security.Beijing,:IEEE,2010:1168–1172. [10] Fan Sijie,Zhao Yaqun,Fan Sijie.Analysis of cryptosystem recognition scheme based on Euclidean distance feature extraction in three machine learning classifiers[J].Journal of Physics(Conference Series),2019,1314(1):012184. doi: 10.1088/1742-6596/1314/1/012184 [11] 赵志诚,赵亚群,刘凤梅.基于随机性测试的分组密码体制识别方案[J].密码学报,2019,6(2):177–190. doi: 10.13868/j.cnki.jcr.000293 Zhao Zhicheng,Zhao Yaqun,Liu Fengmei.Scheme of block ciphers recognition based on randomness test[J].Journal of Cryptologic Research,2019,6(2):177–190 doi: 10.13868/j.cnki.jcr.000293 [12] 丁伟,谈程.一种基于密文分析的密码识别技术[J].通信技术,2016,49(10):1382–1386. doi: 10.3969/j.issn.1002-0802.2016.10.022 Ding Wei,Tan Cheng.An approach of identifying cipher based on ciphertext analysis[J].Communications Technology,2016,49(10):1382–1386 doi: 10.3969/j.issn.1002-0802.2016.10.022 [13] Flach P.Machine learning:The art and science of algorithms that make sense of data[M].New York:Cambridge University Press,2012,39–46. [14] Bassham L,Rukhin A,Soto J,et al.A statistical test suite for random and pseudorandom number generators for cryptographic applications[EB/OL].(2010–09–16)[2021–03–20].https://tsapps.nist.gov/publication/get_pdf.cfm?pub_id=906762. [15] Friedman J H.Greedy function approximation:A gradient boosting machine[J].The Annals of Statistics,2001,29(5):1189–1232. doi: 10.1214/aos/1013203451 [16] Fraz M M,Remagnino P,Hoppe A,et al.An ensemble classification-based approach applied to retinal blood vessel segmentation[J].IEEE Transactions on Biomedical Engineering,2012,59(9):2538–2548. doi: 10.1109/TBME.2012.2205687 [17] Baccour L.Amended fused TOPSIS-VIKOR for classification (ATOVIC) applied to some UCI data sets[J].Expert Systems with Applications,2018,99:115–125. doi: 10.1016/j.eswa.2018.01.025 [18] Esfahani H A,Ghazanfari M.Cardiovascular disease detection using a new ensemble classifier[C]//Proceedings of the 2017 IEEE 4th International Conference on Knowledge-Based Engineering and Innovation.Tehran:IEEE,2017:1011–1014. [19] Amin M S,Chiam Y K,Varathan K D.Identification of significant features and data mining techniques in predicting heart disease[J].Telematics and Informatics,2019,36:82–93. doi: 10.1016/j.tele.2018.11.007 [20] Sun Shaolong,Wang Shouyang,Wei Yunjie.A new ensemble deep learning approach for exchange rates forecasting and trading[J].Advanced Engineering Informatics,2020,46:101160. doi: 10.1016/j.aei.2020.101160[LinkOut [21] 朱敏,张永清,李梦龙,等.基于集成学习方法的蛋白质相互作用预测[J].四川大学学报(工程科学版),2011,43(3):68–75. doi: 10.15961/j.jsuese.2011.03.003 Zhu Min,Zhang Yongqing,Li Menglong,et al.Prediction of protein-protein interactions based on ensemble learning[J].Journal of Sichuan University(Engineering Science Edition),2011,43(3):68–75 doi: 10.15961/j.jsuese.2011.03.003 [22] Sun Wei,Trevor B.A stacking ensemble learning framework for annual river ice breakup dates[J].Journal of Hydrology,2018,561:636–650. doi: 10.1016/j.jhydrol.2018.04.008 [23] Sharif S O,Mansoor S P.Performance evaluation of classifiers used for identification of encryption algorithms[C]//Proceedings of the 2011 International Conference on Advances in Information and Communication Technologies.Washington D.C.:ACEEE,2011:172–175. [24] Manjula R,Anitha R.Identification of encryption algorithm using decision tree[M]//Advanced Computing.Berlin:Springer,2011:237–246. [25] 李洪超.基于密文特征的密码算法识别研究[D].西安:西安电子科技大学,2018. Li Hongchao.Cipher-text features based cipher system recognition[D].Xi’an:Xidian University,2018. [26] Cheon J H,Kim D,Kim Y,et al.Ensemble method for privacy-preserving logistic regression based on homomorphic encryption[J].IEEE Access,2018,6:46938–46948. doi: 10.1109/ACCESS.2018.2866697










































































































